The Overuse of Microservices
Why common microservice practices are often counter-productive for robust distributed systems

Programming enthusiast drawn to distributed systems at scale. Extensive experience across infrastructure, big data, cloud computing, low-latency trading systems, static analysis, and an unlikely number of languages and technologies.
Every programmer knows not to use monolithic architectures, and microservices have become the default choice for distributed systems. Smaller is better, to a limit: a config microservice; a microservice to abstract database access; a microservice for incoming requests; and so on. Each microservice will then be delightfully simple, and all problems will vanish. Right?
Not so fast.
Each microservice might be simple and robust, but their interactions are neither. The hardest part about distributed systems is that they are, well, distributed. Inter-service communication and coordination come with a wonderland of race conditions and unlikely failures. Bugs love such fertile ground. And, by construction, micro-services add a whole lot of it.
That does not mean we should revert to monoliths. But blindly making each individual service "simple" overshoots the target and makes the overall system vastly more complex and thereby error-prone. We should recognize the tradeoffs involved.
Hard boundaries
A service is fundamentally some code running across multiple machines (or "nodes"), accessed via network only. Nowadays, a service is typically deployed as Kubernetes pods running on a public cloud. Service encapsulation provides a hard boundary:
Runtime: the local execution environment and resources, such as cpu/memory, are isolated from external code. Usually, a service is written in a single language.
Contract: a service exposes an RPC API that defines its interactions. A service may also receive messages via a message broker or event bus, although external requests are usually made as direct calls.
Deployment: service instances are deployed and operated as a unit. There may be a release cadence for updates if disruptive to do so. There is no such thing as a zero-risk deployment, so services lower in the stack are typically deployed infrequently (or risk being branded "unreliable" by their callers).
Responsibility: a single team (and on-call rotation) usually scopes, supports, and deploys any given service. Although not apparent to the naive, this has real technical implications that may not align with the goals of the overall system.
These boundaries are hard because they are expensive and difficult to change once in use. For example, merging two services written in different languages is practically impossible and will require a rewrite of at least one. But when done well, service decomposition offers overwhelming improvements over a monolithic architecture and allows easy use of complex dependencies, such as SQL databases and message brokers. Such services are cornerstones.
Soft failures
Each service can fail individually. That much is obvious, yet the implications are less so. The hard failure cases, where a microservice is 100% down, are easiest to anticipate and reason about but relatively rare in practice.
However, at scale, soft failures happen all the time: slowness; partial failures; inter-service request timeouts; bottlenecks; backlog spikes; resource exhaustion; and so on. Handling each requires attention, ingenuity, and a dash of foresight. The more services, the harder it is to catch them all. Not exactly rocket science.
For example, a subtle soft failure is the timeout mismatch: A calls B calls C, but A's timeout is shorter than B's timeout. First, everything works just fine. But under load, if C is too slow, A will time out before B and retry its request to B. B ends up discarding the first successful but too-slow response. A is now racing with itself and indirectly hammers C with duplicate requests. Until something backs down, the system will struggle to recover. Ouch.
It gets worse.
Microservices routinely break up semantically-coupled functionality and introduce failure modes, such as the timeout mismatch, where none need to exist. It's counter-productive but too often only recognized in hindsight when these failures happen in production, which will invariably be on a Saturday evening during peak hours. Why? Because that's when the system is stressed and soft failures proliferate.
When it rains, it pours.
In the vast world of soft failures, of particular importance is atomicity. Here, microservices breed complications that impact correctness.
Atomicity at "The Usual Pizza"
"The Usual Pizza" is an online (fictional) pizzeria that caters to repeat customers. Their signature feature is the 1-click reorder: customers can reorder "the usual" in a single request with no other information. Optionally, customers can update which pizza is "the usual" and their address as part of an order.
The system is implemented as three stateless microservices:
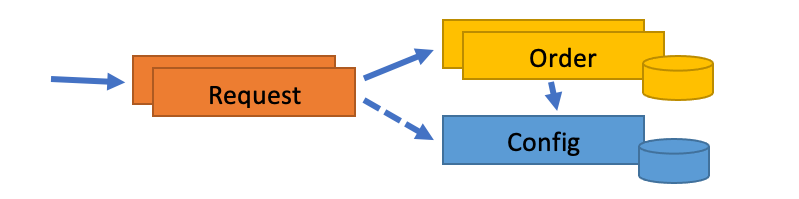
Request validates and authenticates reorder requests, updates address and "the usual" if needed, and then places the order with the Order service.
Config stores the address and "the usual" selection for each customer. Each can be retried or updated individually. It's otherwise a standard CRUD service where the data is persisted in an external database.
Order handles "usual order" requests. First, it retrieves the address and "the usual" selection from the config service. It then records the order in an external database, where a unique order id is generated and returned as confirmation as part of the database transaction.
Each microservice is simple, well-rounded, and can be scaled independently. Although the 1-click reorder is slightly contrived, you have surely seen similar systems before in production. When launched, such a system appears to work perfectly well.
Consider first: what does "work well" mean in practice, i.e., how do we define correct behavior? It is not always straightforward, but it usually boils down to the system behaving as customers expect. Unfortunately, customers have a knack for behaving in ways engineers don't expect, such as temporarily ordering food for someone else. At any rate, customers make a single reorder request to the Request service and expect it to either succeed or fail (but mostly succeed). If it fails, they may try again.
Unfortunately, these expectations - however reasonable - clash with some common atomicity problems prevalent with microservices:
Partial failures. The Request service is promising atomic behavior to its callers, but it uses several primitives, which makes it difficult to honor that promise. For example, if a request, A, updates the address and "the usual," then it may succeed in updating only the address (due to a failure from the Config service, say, or a crash). That leaves the system in an inconsistent state:
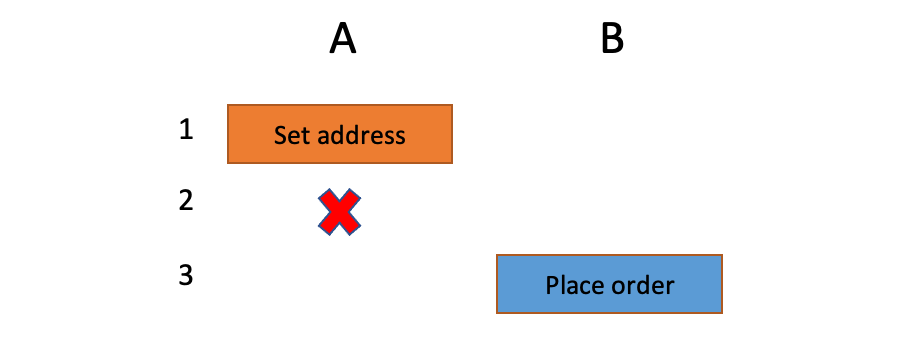
The subsequent plain request, B, will have the prior "the usual" delivered to the updated address. Not expected.
Race conditions. Even in the successful case, inconsistency is possible. For example, a customer who shares an account and always provides an address and "the usual" places two orders, A and B, concurrently may see interleaved execution:
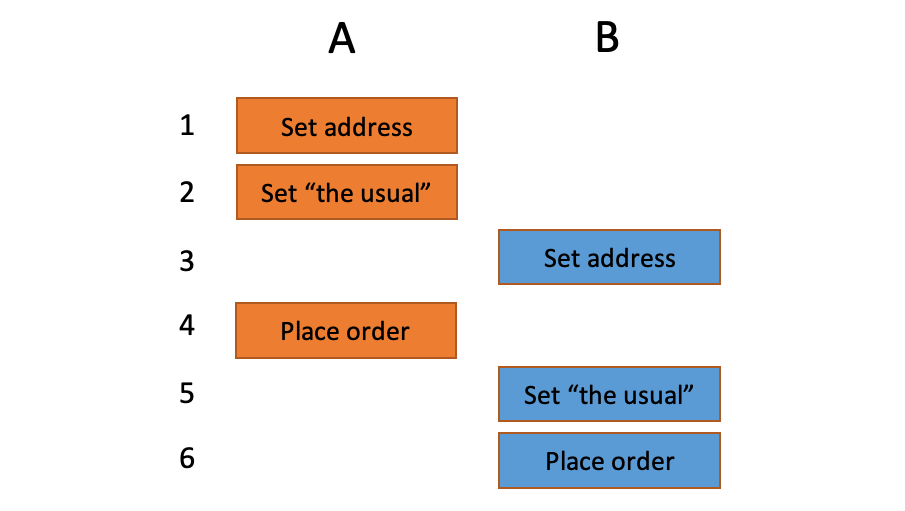
There are no failures, but A was delivered to B's address. Oops. That's another 1-star review.
There are solutions to every problem here. But it's easy to fall into the trap of fighting complexity with more complexity:
To prevent partial failures, we could make the Config service update both the address and "the usual" in a single call. However, that's a contract change, which might get pushback from the Config team. The Request service could instead undo a successful update, but the undo operation might fail. Either way, it does not solve the problem: a later failure in place order would leave the config changes hanging. Finally, we could record inflight orders somewhere to ensure cleanup, which adds persistent storage or another dependency to the Request service. Hmmm.
To prevent interleaved execution, we could pass the address and "the usual" to the Order service with the order request. That's reasonable, but also a contract change. That change also has a subtle effect: callers of Order can bypass the Config service altogether. Will that be a problem? Hard to say. Or we could serialize order processing using a durable queue or message broker, which introduces an extra dependency for an unlikely (and not willingly supported) corner case. So many choices.
For "The Usual Pizza," there is a simpler alternative.
Its atomicity problems are a consequence of microservice overuse. A single service (with a single database) would avoid these problems by doing the config updates and retrieval in the same database transaction as order placement. The Request, Config, and Orders services would be modules instead and forego rigid internal service boundaries.
Of course, that approach will only work in some situations. For example, external services cannot be changed or merged, and some actions are inherently non-transactional. But we don't have to invent problems for ourselves.
Pebbles vs. Bricks
Microservices architectures focus on individual services with hard boundaries. But the soft failure complexity is too often overlooked, and many microservices end up like pebbles: simple, plentiful, and smooth. But close to useless as building blocks in the overall system.
Instead, identify soft failures and their implications for the overall system when creating service boundaries. If done with restraint, services become more like bricks: robust and square, i.e., encapsulate - not export - non-trivial functionality and tricky failure modes. Contrary to the microservice narrative, a trivial service is more often a candidate for elimination, not praise.
The robustness of a system is a reflection of what failure modes it tolerates. Not every failure mode is necessarily worth handling, and there is rarely a "best" solution. Pragmatic tradeoffs must be made. But be careful not to overestimate the patience of customers: a nuisance at scale is a crisis. That 99.9% success rate is a 0.1% failure rate. The tolerance threshold inches down with every new customer. And, once lost, fundamental properties such as atomicity can be impossible to reinstate later.


